About SingleStore Helios
On this page
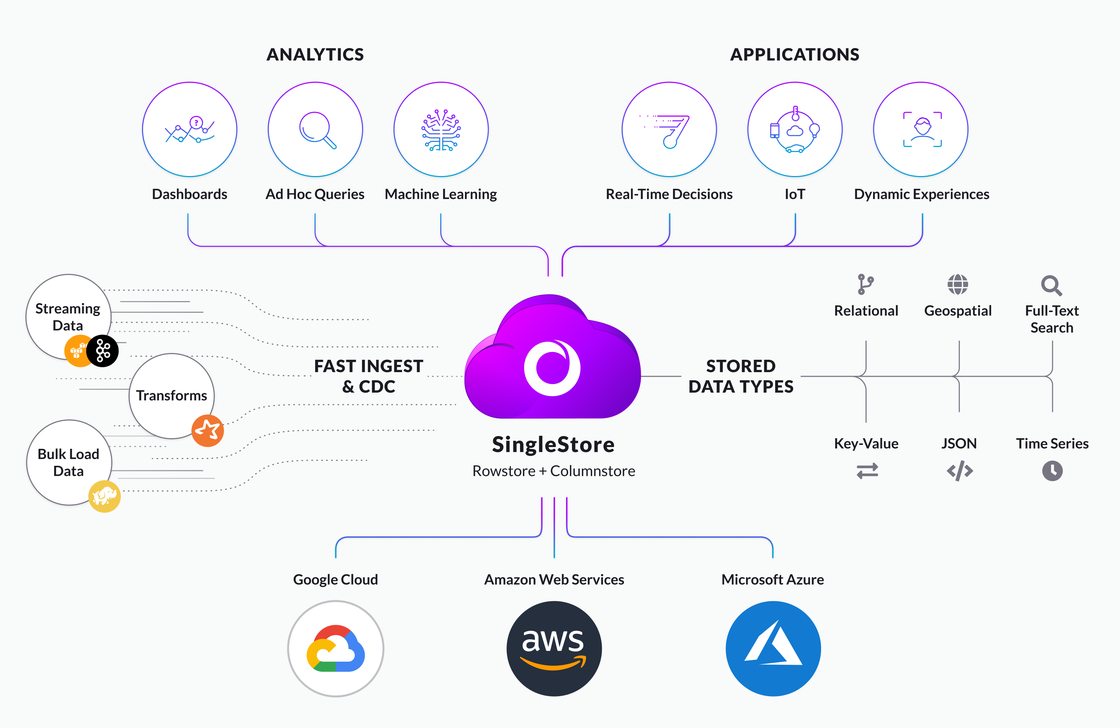
SingleStore Helios is a distributed, relational database with optimized speed and scalability to support data-intensive and real-time applications.
Key Features of SingleStore Helios
Speed and Scalability
-
Maximum Performance: An optimized query engine and modern architecture allow SingleStore to process complex transactional (OLTP) and analytical (OLAP) workloads at record speeds.
-
High Scalability: Infinite elasticity enables you to easily scale your applications, while offering separation of storage and compute.
Fully Multi-cloud Database
-
As a fully multi-cloud database, SingleStore gives you complete control over where you deploy and run your environment thereby avoiding vendor lock-in.
Simplicity and Connectability
-
SQL: SingleStore features familiar SQL tooling and is MySQL wire protocol compatible, thereby eliminating the need for specialized databases and simplifies your application architecture.
-
Connectors: SingleStore includes connectors for common languages, frameworks, and tools.
-
Multi-Model: SingleStore supports multiple data types including JSON, time-series, geospatial and full-text search.
-
API-Driven: Designed for developers, SingleStore features API-driven workflows and direct integrations to support serverless application development.
Enterprise Security Protocols
-
Secure-by-Design: Backed by reliable end-to-end encryption, SingleStore empowers users to select a secure method of authentication and authorization best suited for your enterprise.
-
Enterprise Compliance: SingleStore has industry-leading security certifications including ISO/IEC 27001, SOC Type 2, and Privacy Shield.
It is also fully compliant with CCPA, GDPR, and HIPAA requirements. -
Secure Integration: SingleStore allows secure, permitted authorization from web, mobile and desktop applications through security tools like Okta, Ping, and Azure AD (AAD).
Additional Information
Quickstart: Loading Data and Running Queries - walks you through using the Cloud Portal to create a database, load sample data quickly, and then run some queries against that data.
Designing for Multi-tenant Applications - explains the various models and trade-offs available for a multi-tenancy SaaS application.
Visit https://www.
In this section
Last modified: July 4, 2023