Configure Monitoring
On this page
Overview
SingleStore’s native monitoring solution is designed to capture and reveal SingleStore cluster events over time.
Terminology
Throughout this guide, the cluster that is being monitored is referred to as the Source
cluster, and the cluster that stores the monitoring data is referred to as the Metrics
cluster.metrics database.
High-Level Architecture
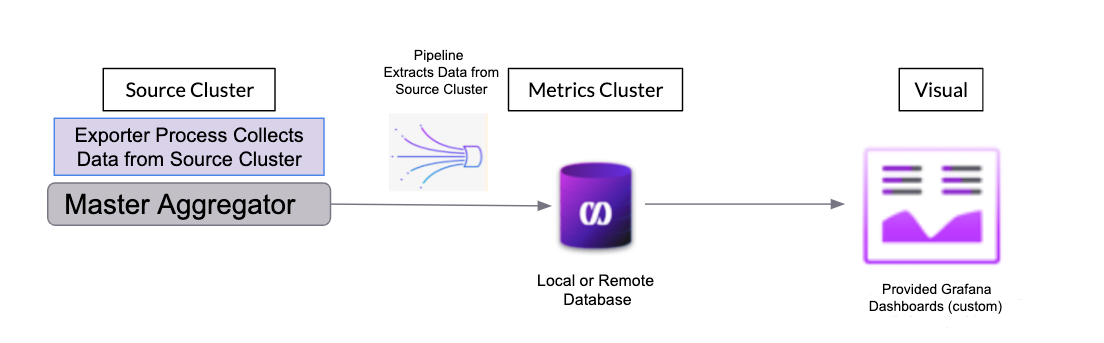
In SingleStore’s native monitoring solution, the Metrics cluster utilizes a SingleStore pipeline to pull the data from the exporter process on the Source cluster and store it in a database named metrics.metrics database can either reside within the same cluster as the Source cluster, or within a dedicated cluster.
When these event data is then analyzed through the provided Grafana dashboards, trends can be identified and, if necessary, actions taken to remediate issues.
The provided Grafana dashboards include:
|
Dashboard |
Description |
|---|---|
|
Cluster View |
Provides a “bird's-eye view” of a single SingleStore cluster. |
|
Detailed Cluster View by Node |
Provides a view into resource utilization by node and host. |
|
Historical Workload Monitoring |
Statistics for parameterized query execution including run count, time spent, and resource utilization. |
|
Memory Usage |
Granular breakdown of memory use for a host. |
Prerequisites
Note
These instructions have been developed for SingleStore clusters that have been installed and deployed via . or . packages as a sudo user.
If your cluster was deployed via tarball as a non-sudo user, change to the directory (cd) in which singlestoredb-toolbox was untarred and run all sdb-admin commands as ..
SingleStore Toolbox is recommended for managing the clusters as automation during setup is provided through sdb-admin commands.
Note that the Grafana instructions will require a user with sudo access to install and configure the associated Grafana components.
For HTTP Connections
-
A SingleStore 7.
3 or later cluster to monitor (the Source cluster); SingleStore 8. 5 or later to collect trace events. -
Optional: A separate SingleStore 7.
3 or later cluster used to collect monitoring data (the Metrics cluster); SingleStore 8. 5 or later to collect trace events. The Source and Metrics clusters can be the same if the cluster is not considered business-critical. Otherwise, a separate Metrics cluster is recommended, which: -
Must be open to local (internal) network traffic only, and not open to the Internet.
-
Must only contain monitoring data from one or more Source clusters.
-
Should have two aggregator nodes and two leaf nodes, each with 2TB disks and with high availability (HA) enabled (SingleStore recommended)
-
-
Clusters are managed with SingleStore Toolbox 1.
9. 3 or later. -
A Grafana instance (the latest version of Grafana) that can access the Metrics cluster.
For HTTPS Connections
Similar to the HTTP connection prerequisites, with additional requirements:
-
Each Source and Metrics cluster must be running SingleStore 7.
6. 24 or later, or SingleStore 7. 8. 19 or later; SingleStore 8. 5 or later to collect trace events. -
Clusters are managed with SingleStore Toolbox 1.
14. 2 or later. -
A server SSL certificate and a key signed with a CA certificate.
This guide assumes that: -
The server SSL certificate file is named
server-cert..pem -
The server key file is named
server-key..pem Note that the server key may be protected with a passphrase. -
The CA certificate file is named
ca-cert..pem -
Refer to Generating SSL Certificates for an example of generating these certificates.
-
Monitoring License
If the size of the cluster that is hosting the monitoring data is 4 units or under, it can use a free tier license.
Port Configuration
|
Default Port |
Used by |
Invoked by |
|---|---|---|
|
|
Grafana |
User browser |
|
|
SingleStore |
|
|
|
|
SingleStore pipelines |
In this section
Last modified: January 2, 2024